cv - 패턴을 일치시켜 classification을 수행, feature 기반
NLP
LISTEN vs SILENT
두 단어는 같은 아스키 값들을 가진다. but 반대의 의미
단어마다 값이 있고, 같은 단어에 대해 값이 동일하도록
ex)
i love my cat. / i love my dog
1 2 3 4 1 2 3 5
"Tokenizer(num_words=고유단어 개수)"
Publications
ML Engineer
rishabhmisra.github.io

 |
fit 호출 시 단어 인덱스 생성, 토크나이저 초기화 |
- IMDB dataset(movie review)
http://ai.stanford.edu/~amaas/data/sentiment/
Sentiment Analysis
Publications Using the Dataset Andrew L. Maas, Raymond E. Daly, Peter T. Pham, Dan Huang, Andrew Y. Ng, and Christopher Potts. (2011). Learning Word Vectors for Sentiment Analysis. The 49th Annual Meeting of the Association for Computational Linguistics (A
ai.stanford.edu
K9라는 단어를 본 적이 없어도 K9가 개와 관련된 개와 비슷한 것을 의미한다는 것을 알고리즘에 알릴 수 있습니다.
built in dataset - tfts(tensorflow data services)
'embedding'
어떤 단어와 관련단어를 다차원 공간에서 벡터로 묶음
<조건>
1. python 3.0ver
2. tensorflow 2.0ver
(그보다 낮을 경우 tf.enable_eager_execution()실행 필요
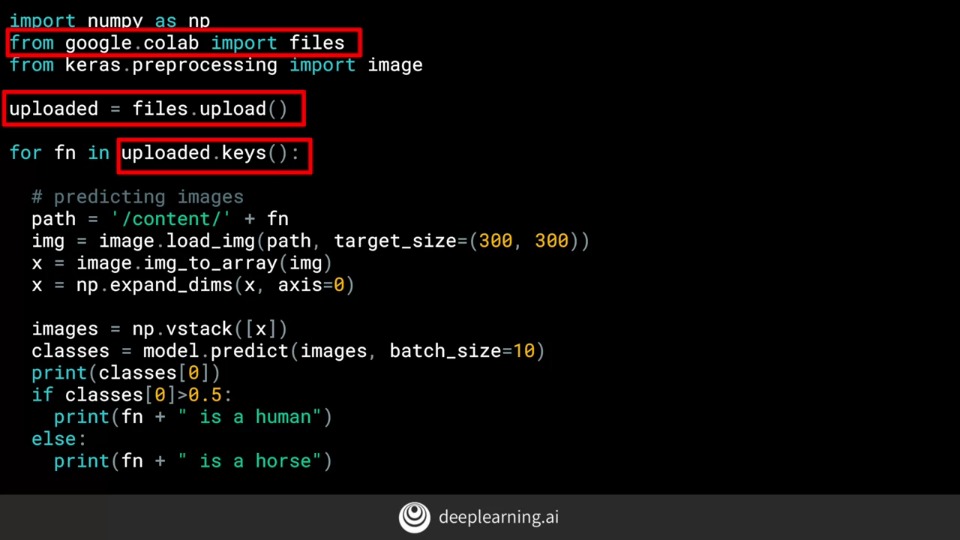
이제부터 살펴 보겠습니다. TensorFlow에서 이번 주 코드 작업을 시작하기 전에 고려해야 할 몇 가지 사항이 있습니다.
첫 번째는 사용중인 TensorFlow 버전입니다. 이 코드를 사용하여 결정하십시오. 또한 여기에서 사용하는 모든 코드는 Python 3에 있습니다. Python 2를 사용하는 경우 약간의 차이가 있으므로 Colab을 사용하는 경우 환경을 3으로 설정할 수 있습니다. 자신의 환경에서이 작업을 수행하는 경우 몇 가지 사항을 변경해야 할 수도 있습니다. 이전 코드에서 TensorFlow 1.x를 제공 한 경우 계속 진행하려면이 코드 줄이 필요합니다. 그것이 2.x를 주었다면,
TensorFlow 2.0에서 기본적으로 더 빠른 실행이 활성화되어 있기 때문에 아무것도 필요하지 않습니다. Google Colab을 사용하는 경우 TensorFlow 데이터 세트가 이미 설치되어 있어야합니다. 그것들이 없으면이 코드 줄로 쉽게 설치됩니다. 이제 TensorFlow 데이터 세트를 가져올 수 있으며이 경우에는 tfds라고합니다. imdb 리뷰를 사용하여 tfds.load를 호출하고 문자열 imdb reviews를 전달하면 imdb의 데이터와이 코드로 메타 데이터를 반환합니다.
데이터는 교육용 25,000 개 샘플과 테스트 용 25,000 개 샘플로 나뉩니다. 나는 이것을 이렇게 나눌 수 있습니다. 이들 각각은 25,000 개의 각 문장과 레이블을 텐서로 포함하는 반복 가능 항목입니다.
지금까지는 문장 배열에 Cara의 토크 나이저와 패딩 도구를 사용 했으므로 약간의 변환이 필요합니다. 우리는 이렇게 할 것입니다. 먼저 훈련 및 테스트 데이터에 대한 문장과 레이블이 포함 된 목록을 정의하겠습니다. 이제 문장과 레이블을 추출하는 훈련 데이터를 반복 할 수 있습니다.
S와 I의 값은 텐서이므로 NumPy 메소드를 호출하여 실제로 값을 추출합니다. 그런 다음 테스트 세트에 대해서도 동일한 작업을 수행합니다.
다음은 검토의 예입니다. 이 슬라이드에 맞게 잘랐지만 tf.tensor로 저장되는 방법을 볼 수 있습니다.
마찬가지로, 여기에도 텐서로 저장된 많은 레이블이 있습니다. 값 1은 긍정적 인 리뷰를 나타내고 0은 부정적인 리뷰를 나타냅니다. 교육 할 때 레이블은 NumPy 배열 일 것으로 예상됩니다. 방금 만든 레이블 목록을이 코드를 사용하여 NumPy 배열로 바꿉니다.
다음으로 문장을 토큰 화합니다. 코드는 다음과 같습니다. 리터럴의 함수 시퀀스를 통해 피싱 한 다음 변경하는 대신 하이퍼 파라미터를 가장 쉽게 변경하고 편집 할 수 있도록 하이퍼 파라미터를 맨 위에 배치했습니다.
이제 이전과 마찬가지로 토크 나이저와 패드 시퀀스를 가져옵니다. 토크 나이저 인스턴스를 생성하여 어휘 크기와 원하는 어휘 토큰을 제공합니다.
이제 훈련 데이터 세트에 토크 나이저를 적용 할 것입니다.
단어 색인이 생성되면 이제 단어가 포함 된 문자열을 해당 단어에 대해 만든 토큰 값으로 바꿀 수 있습니다.
이것이 시퀀스라고하는 목록입니다. 이전과 마찬가지로 문장의 길이는 변합니다. 따라서 maxlength 매개 변수에 의해 결정된 모든 동일한 길이가 될 때까지 시퀀스 된 문장을 채우거나 자릅니다.
그런 다음 테스트 시퀀스에 대해 동일한 작업을 수행합니다. 단어 색인은 학습 세트에서 파생 된 단어이므로 테스트 시험에서 더 많은 어휘 토큰을 볼 수 있어야합니다.
이제 신경망을 정의 할 차례입니다. 이 줄을 포함하는 것을 제외하고는 지금까지 매우 친숙해 보일 것입니다. 이것이 TensorFlow에서 텍스트 감정 분석의 핵심이며, 이것이 바로 마술이 일어나는 곳입니다.
문장 속의 단어, 비슷한 의미일 수록 가깝다.
ex) 이영화는 지루하고 재미없었어. 이 영화는 재미있고 흥미로웠어
-> 지루& 재미없다, 재미 & 흥미롭다
tf.Tensor사용
embedding결과 -> 문장 길이만큼의 2D array
flatten() 사용 -> 출력벡터의 크기 때문에 해당 길이만큼이 안나옴
해결방법) GlobalAveragePooling1D()를 사용한다.
sequence에서 value와 key를 뒤집어야 한다.
16차원 값 -> vector.tsv로
실제 단어 -> meta.tsv로
(projector.tensorflow.org)
 |
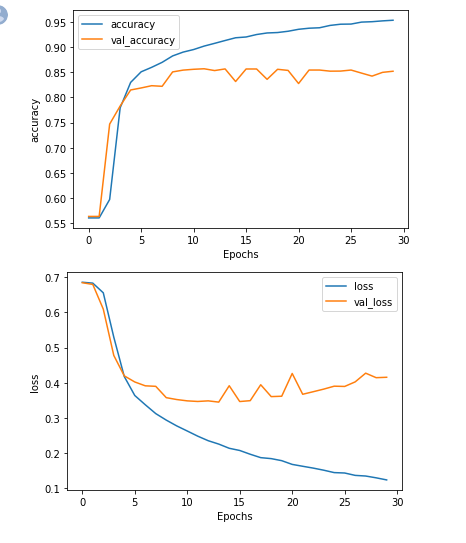
hyper parameter를 조정하면서 val_loss확인
 |
 |
| max_length=1000과 truncate = pre, padding = post | max_length=1000과 truncate = post, padding = pre |
 |
 |
| max_length=1000과 truncate & padding = post | max_length=1000과 truncate & padding = pre |
 |
 |
| max_length=32와 truncate & padding = pre | max_length=32와 truncate & padding = post |
 |
 |
| max_length = 1000, embedding_dim = 32(before 16) | max_length = 1000, vocab_size = 1000(before 10000) |
https://github.com/tensorflow/datasets/tree/master/docs/catalog
tensorflow/datasets
TFDS is a collection of datasets ready to use with TensorFlow, Jax, ... - tensorflow/datasets
github.com
https://www.tensorflow.org/datasets/catalog/overview
TensorFlow Datasets
Except as otherwise noted, the content of this page is licensed under the Creative Commons Attribution 4.0 License, and code samples are licensed under the Apache 2.0 License. For details, see the Google Developers Site Policies. Java is a registered trade
www.tensorflow.org

 |
bytes -> text들은 byte level로 encode되어 있다. |
- subwords text encoder
https://www.tensorflow.org/datasets/api_docs/python/tfds/features/text/SubwordTextEncoder
tfds.features.text.SubwordTextEncoder | TensorFlow Datasets
Invertible TextEncoder using word pieces with a byte-level fallback. Inherits From: TextEncoder tfds.features.text.SubwordTextEncoder( vocab_list=None ) Used in the notebooks Encoding is fully invertible because all out-of-vocab wordpieces are byte-encoded
www.tensorflow.org
사전 훈련 된 하위 단어 토크 나이저가 있으므로 하위 단어 속성을 확인하여 어휘를 검사 할 수 있습니다.
하위 단어의 의미는 종종 의미가 없으며 의미있는 의미를 갖는 순서로 조합 할 때만 사용됩니다
- ValueError: logits and labels must have the same shape ((None, 1) vs ())
train_data = train_data.map(lambda x_text, x_label: (x_text, tf.expand_dims(x_label, -1)))
test_data = test_data.map(lambda x_text, x_label: (x_text, tf.expand_dims(x_label, -1)))
https://developers.google.com/machine-learning/glossary?hl=ko
https://developers.google.com/machine-learning/crash-course/embeddings/video-lecture
https://subinium.github.io/Keras-6-1/
- purpose of embedding dimensions
: number of dimensions for the vector representing the word encoding
- num_words=n parameter do..
; specifies the maximum number of words to be tokenized and picks the most common 'n' words
(가장 빈도 수 높은 n개의 단어)

단어 순서가 바뀌면 문장의 의미가 크게 바뀔 수 있다.
RNN -> 컨텍스트가 타임 스탬프 보존, 더 긴 문장에서는 손상될 수 있다.
LSTM -> 셀 상태(컨텍스트를 끝까지 전달하는 컨베이어 벨트),
단어가 하위 단어로 나뉘어 질 때 단어의 문맥을 따르기가 어려웠으며 하위 단어의 토큰이 나타나는 순서가 의미를 이해하는 데 매우 중요해 졌기 때문입니다
# RNN

x input, y - output

x0는 네트워크를 통해 모든 요소에 공급된다.
https://www.coursera.org/lecture/nlp-sequence-models/deep-rnns-ehs0S
Deep RNNs - Recurrent Neural Networks | Coursera
Video created by deeplearning.ai for the course "Sequence Models". Learn about recurrent neural networks. This type of model has been proven to perform extremely well on temporal data. It has several variants including LSTMs, GRUs and ...
www.coursera.org
context를 통해 다음 단어를 유추할 수 있다. Syntactic Issue
ex) today has a beautiful blue~
==> today has a beautiful blue sky
#LSTM
cell state means that they carry context along with them,

RNN에서 유지되는 context이외에 'cell state'라 불리는 추가 컨텍스트 파이프라인 존재
양방향, 단방향 가능/ 장,단기 메모리
https://www.coursera.org/lecture/nlp-sequence-models/long-short-term-memory-lstm-KXoay
Long Short Term Memory (LSTM) - Recurrent Neural Networks | Coursera
Video created by deeplearning.ai for the course "Sequence Models". Learn about recurrent neural networks. This type of model has been proven to perform extremely well on temporal data. It has several variants including LSTMs, GRUs and ...
www.coursera.org
 |
tf.keras.layers.LSTM(x) -> x = 해당 레이어에서 원하는 출력 수 |
 |
단방향이 아닌 Bidirectional이었기에 64가아닌 128 크기 |
 |
return_sequences = True -> LSTM레이어 여러개 쌓으려면(?) |
 |
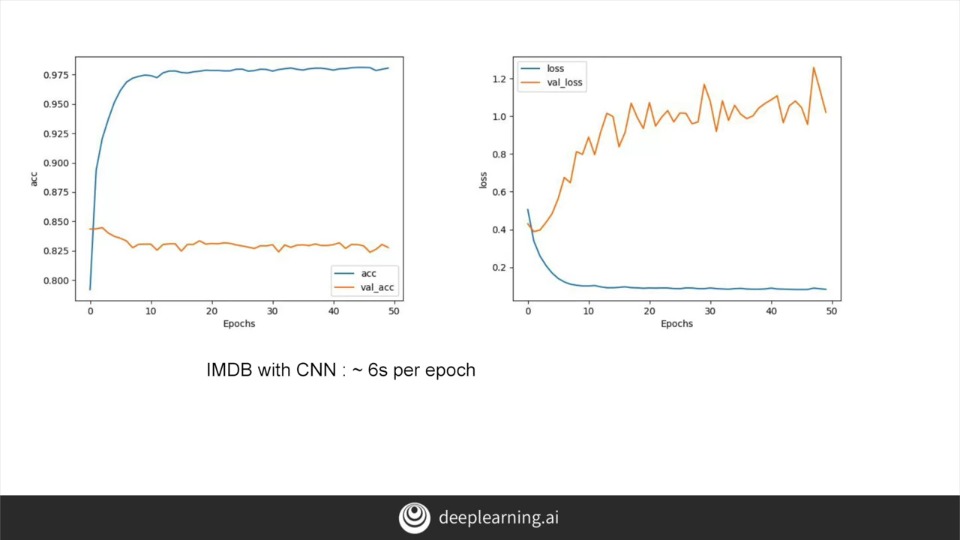
single LSTM 에 비해 Multi LSTM이 더 smooth 한 결과를 내놓음
-> 10epoch에서는 둘다 결과가 비슷해보이지만 epoch이 50가까이 되면 multi가 훨씬 좋음
-> single은 변동이 커 신뢰할 수 없는 정확도를 보인다.
다른형태의 네트워크를 같이 쓸 때는 parameter 조정을 유의(?)
 |
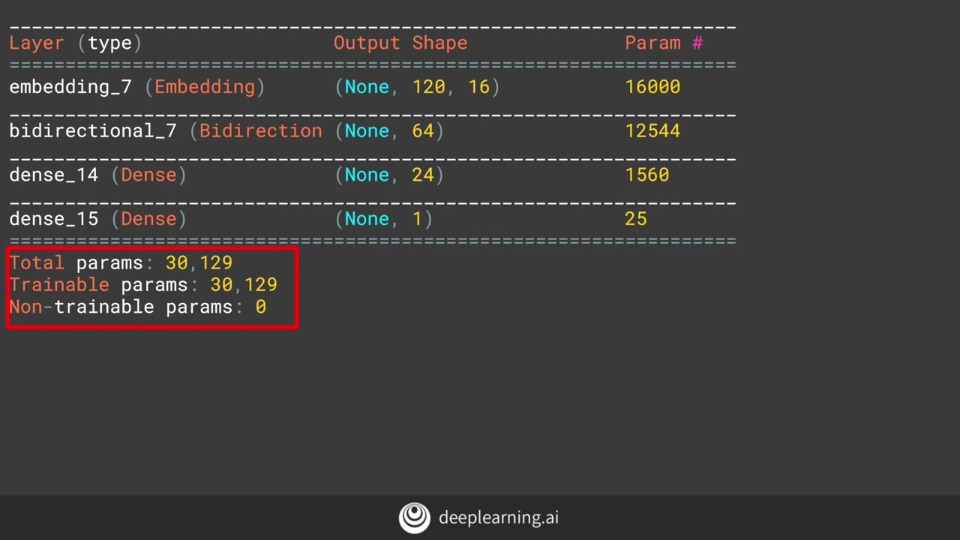
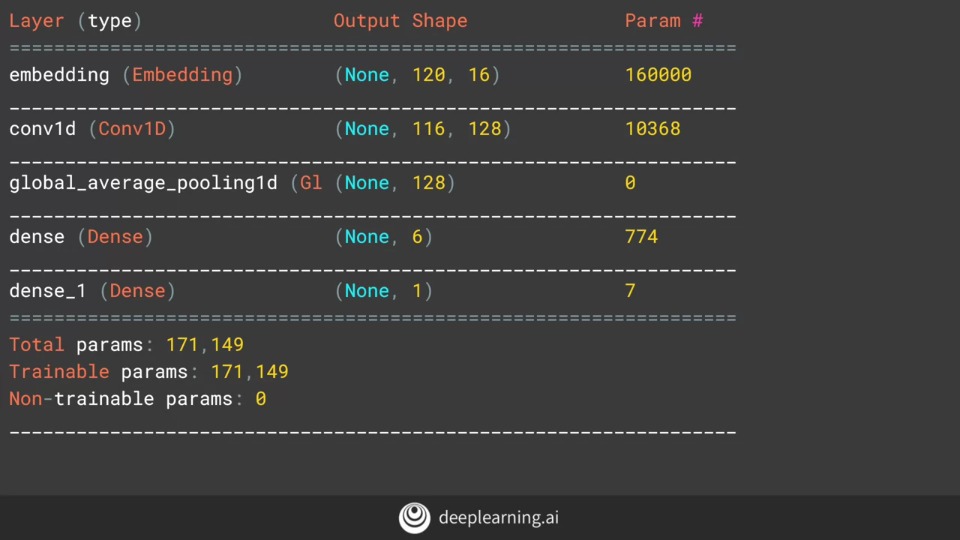
5개의 단어에 대해 128개의 필터 처음과 끝의 2 단어씩 깎기 때문에 116단어가 남음 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
| 기본 | LSTM | GRU(different type of RNN) | Convolution |
-> 모두 over fitting문제 발생
image에 비해 text가 더 overfitting 많이 발생: validation에 그 전에 보지 못했던 어휘가 훨 많아서
key word, value token
- Sequence model
 코드 |
 결과 |
 n-gram sequence 생성 |
 n-gram sequence 생성 결과 |
 가장 긴 문장을 찾아 그 길이에 맞추어 padding 시킴 |
 pre padding을 사용 |
 마지막 토큰을 레이블로 사용 |
 마지막 토큰을 레이블로 사용 |

sentence 문장
x -> 마지막 토큰을 제외한 SEQUENCE
label -> 마지막 토큰, 레이블로 사용
y -> one-hot-encode, label번호만 1로 표기(이 경우는 70번째원소가 1로 표기)
-> tf.keras.utils.to_categorical(labels, num_classes = len(word_index) + 1
word_index 갯수 +1 = total number of unique words that are in the corpus
처음 예측은 높은 확률로 말이 되는 문장을 만들어낸다. 하지만 문장의 길이가 길어질수록 점점 그 확률이 낮아져 말이 안이어짐
 |
total_words -> 모든 단어를 다 다룸 64 -> number of dimensions input_length -> max -1 -> 마지막 단어를 잘라서 label을 구하므로 max -1 길이 |
 |
문장의 반복 -> LSTM이 context를 앞으로만 전달하기 때문 -> Bidirectional하게 바꾸어준다. |
----------
 |
 lawrence는 없는 단어라서 무시됨 |
 training_set과 맞춤 |
 |
 sequence에서 그 다음에 확률이 높은 토큰 선택 |
 역방향 조회를 수행하여 토큰을 다시 단어로 바꾸고 시드 텍스트에 추가 |
https://www.tensorflow.org/tutorials/text/text_generation
순환 신경망을 활용한 문자열 생성 | TensorFlow Core
Note: 이 문서는 텐서플로 커뮤니티에서 번역했습니다. 커뮤니티 번역 활동의 특성상 정확한 번역과 최신 내용을 반영하기 위해 노력함에도 불구하고 공식 영문 문서의 내용과 일치하지 않을 수
www.tensorflow.org
출처: coursera, natural language processing in tensorflow 과정
'공부일지 > etc' 카테고리의 다른 글
| Pandas (0) | 2020.07.21 |
|---|---|
| Tensorflow in Practice 3, Sequence Model (0) | 2020.06.28 |
| 아낰혼다 (0) | 2020.06.24 |
| tensorflow, keras 설치하기 (0) | 2020.06.17 |
| #Data Mining Task (0) | 2020.06.03 |