시계열 Time Series
주식, 날씨 예측, 역사적 추세 등 시간 요소가 있는 것들
univariate - 단일 값
multivariate - 여러값
1. 데이터 기반 미
래 예측
2. 과거를 투영하여 현재 위치에 어떻게 도달했는지 확인(imputation), 비어있는 데이터 채우기
3. anomaly detection
4. 해당 Time Series의 패턴찾기
 |
 |
 |
 |
| trend 특정 방향으로 이동하는 추세 |
seasonality 패턴이 예측가능한 간격으로 반복 |
trend & seasonality 두 가지 융합 |
white noise 완전 임의의 값 |
 |
spike -> 다음에 언제 일어날 지, 얼마나 강할지 예측할 수 없음 -> 예측할 수 없는 spike는 innovation이라 불림 빨간 박스 == lag -> lag끼리는 stron autocorrelation이 있음 |
패턴을 찾으면 prediction이 가능해진다.
 |
 |
| 마지막 값을 가져오고 다음 값은 같은 값이라고 예측하는거(?) == naive forecasting -> 현재 그래프 -1 -> 성능 평가하는데 비교되는 baseline으로 사용됨 |
real world trend + seasonality + noise |
- metrics for evaluating performance

| errors = forecasts - actual | 예측 값 - 실제 값(evaluation period동안) |
| mse = np.square(errors).mean() | 예측 성능 평가 제곱을 하는 이유 -> 음수값을 없애기 위해 |
| rmse = np.sqrt(mse) | 에러와 스케일을 비슷하게 하기 위해서 제곱근 사용 |
| mae = np.abs(errors).mean() | 음수를 처리하기 위해 제곱 대신 절댓값 사용 -> mse만큼 큰 오차를 피하기위해 |
| mape = np.abs(errors / x_valid).mean() | 절대 오차값과 절대값 사이의 평균 비율 -> 원래 값과 오차의 크기 비교 가능 |
But if your gain or your loss is just proportional to the size of the error, then the mae may be better.
- Moving Average
 |
간단한 forecasting method는 이동 평균을 계산하는 것 -> 노이즈를 제거하고 curve를 대략적으로 emulate할 수 있음, 예측을 하는건 아님 |
오차를 줄이려면 "differencing" 기술을 사용
-> Time Series에서 trend와 seasonality를 제거하는 기법
-> 임의의 시점 T의 값에서 그 이전 시점(1일, 1달,1년 등) 값과의 차이
 |
1년전과의 차이 -> trend, seasonality 없음 해당 Time Series를 이동 평균을 이용해 forecast를 구함 |
 |
해당 이동 평균을 기존 Series값과 더한다. -> 기존 오차보다 조금 더 개선된 결과를 얻을 수 있다. -> 노이즈가 잔뜩 낀 모습을 볼 수 있음 |
 |
해당 forecast의 이동평균을 구해 smoothe하게 바꿔준다. -> 조금 더 개선된 오차값을 얻을 수 있음 |
Moving Average를 계산할 때는 trailing window 사용
학습 시 window 사용
ex) 30개의 데이터가 입력 X라면 그 바로 다음에 나오는 값이 Label Y가 된다.
-> 1개의 Label에 30개의 feature가 있는셈
y는 시간값이 되고 x는 시계열 value값을 가진다.(
 |
window 설정, 5개씩 -> 이후 줄어드는 이유는 9이후의 데이터가 없기 때문 |
 |
drop_remainder = True 를 이용하여 5개만을 제공하도록 함 |
 |
numpy로 저장한 이후 input X 와 label Y로 나눔 |
 |
데이터 섞기 |
 |
batch |
# RNN & LCM
순차적으로 처리
 |
2개의 recurrent layer와 마지막 dense layer |
 |
3차원의 input을 가짐 첫 번째 차원은 배치 크기 두 번째 차원은 타임 스탬프 세 번째 차원은 각 시간 단계에서 입력의 차원 (univariate일 경우 1, multivariate는 그 크기만큼) |
 |
레이어 재사용 시간 0, zero state를 입력으로 계산 -> 출력 Y0와 다음단계로 공급되는 상태벡터 H0 계산 H0는 X1과 함께 셀에 공급되어 Y1과 H1을 생성하고 이를 계속 반복 => 셀의 출력으로 인해 값이 반복됨 -> 다음단계에 한 단계씩 전달됨 (RNN) |
 |
batch size =4 timestamp = 30 univariate |
 |
output = 4 * 3 full output = 4 * 30 * 3 batchsize = 4이고 neuron은 총 3개이므로 4*3크기의 output이 나온다. |
 |
간단한 RNN에서는 Hn == Yn이다. 즉, H1=Y1, H2=Y2, .... |
 |
시퀀스를 입력하고 싶지만 출력을 원하지 않고 배치의 각 인스턴스에 대해 단일 벡터를 얻으려할때 -> a sequence to vector RNN 마지막 output을 제외하고는 다 무시 return_sequence = True를 통해 |
 |
(None, 1) -> first dimension = batch size -> None으로 설정(어떤 사이즈든) -> RNN이 시퀀스가 어느길이든 다룰 수 있음을 의미 Second dimension= univariate 두 번째 RNN은 return _sequence가 True가 아님 -> 그냥 output만을 내놓음 |
 |
둘 다 True인 경우 sequence to sequence RNN dimension이 맞지않을 수도 있음 |
# Lambda Layer
 |
기존의 2차원 input을 lamda를 통해 3차원으로 변경 |
 |
출력을 100으로 늘려 학습을 돕는다. 기본적으로 RNN의 activatino function은 tanh임 -> 값이 -1 ~ 1 Time Series값은 대게 40, 50, 60등으로 되어 있으니 간단하게 activation 값에 100을 곱해준다. |
#Huber loss
- outlier 에 덜 민감 -> 노이즈에 강함
https://en.wikipedia.org/wiki/Huber_loss
Huber loss - Wikipedia
In statistics, the Huber loss is a loss function used in robust regression, that is less sensitive to outliers in data than the squared error loss. A variant for classification is also sometimes used. Definition[edit] The Huber loss function describes the
en.wikipedia.org
RNN 단점 -> 타임스탬프가 지남에 따라 영향이 감소한다는 것
-> LSTM을 사용해 단점 보완
# LSTM
https://www.coursera.org/lecture/nlp-sequence-models/long-short-term-memory-lstm-KXoay
Long Short Term Memory (LSTM) - Recurrent Neural Networks | Coursera
Video created by deeplearning.ai for the course "Sequence Models". Learn about recurrent neural networks. This type of model has been proven to perform extremely well on temporal data. It has several variants including LSTMs, GRUs and ...
www.coursera.org
 |
clear_session() -> 내부 변수를 지움 lambda layer -> 크기 확장 Bidrectional LSTM -> 32개의 셀, 예측에 미치는 여향을 확인하기 위해 양방향으로 dense Layer -> 예측값을 내놓음 |
 |
 |
LSTM 레이어 추가 더 나은 결과를 볼 수 있다. |
 |
https://www.coursera.org/learn/convolutional-neural-networks/home/welcome
Coursera | Online Courses & Credentials From Top Educators. Join for Free | Coursera
Learn online and earn valuable credentials from top universities like Yale, Michigan, Stanford, and leading companies like Google and IBM. Join Coursera for free and transform your career with degrees, certificates, Specializations, & MOOCs in data science
www.coursera.org
# mini-batch gradient descent
https://www.youtube.com/watch?v=4qJaSmvhxi8
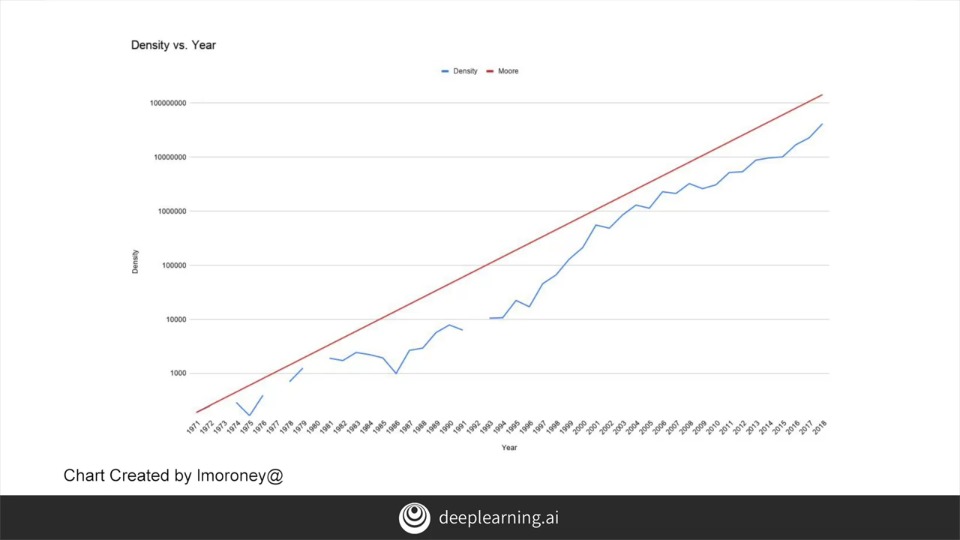
출처: Coursera, Sequences, Time Series and Prediction
'공부일지 > etc' 카테고리의 다른 글
| 한국어 text generator만들어 보기 - konlpy 설치하기 (0) | 2020.07.22 |
|---|---|
| Pandas (0) | 2020.07.21 |
| Tensorflow in Practice 2, Natural Language Processing (0) | 2020.06.27 |
| 아낰혼다 (0) | 2020.06.24 |
| tensorflow, keras 설치하기 (0) | 2020.06.17 |